GeneSNP-VISTA
See also: EcoSNP-VISTA - Visualization of SNPs and discovery of recombination points in microbial populations
System requirements
GeneSNP-VISTA can be executed on any Windows Linux or MacOS X computer with installed Java version 1.4 or higher.
Follow these instructions to install Java on your machine:
Windows |
Linux |
Solaris
Macintosh users should upgrade their OS to 10.1 or better. Additional java upgrades may be available from Apple's download page.
Installation instructions
- download the archive for Windows, MacOS X or Linux
- Save the file on your desktop
- For Mac users unzip and untar the archive GeneSNP-VISTA.mac.tar.gz which will create GeneSNP-VISTA.mac directory. The program will create a folder GeneSNP-VISTA.mac/vismu with several files. After this the archive can be removed.
- For Linux users unzip and untar the archive GeneSNP-VISTA.linux.tar.gz which will create GeneSNP-VISTA.linux directory. The program will create a folder GeneSNP-VISTA.linux/vismu with several files. After this the archive can be removed.
- For windows users Start the GeneSNP-VISTA.exe program by clicking on the icon. The program will create a folder GeneSNP-VISTA/vismu with several files. After this the archive can be removed.
- Windows user can run program by executing the start.bat file
Linux and Mac Users must execute the run file
Note for UNIX users: files cluster must be executable.
User manual
Input files
| File | status | description |
|---|---|---|
| Sequence | mandatory | FASTA format file. Distributive package contains an example file ABO.fsa |
| Pretty base | mandatory | This text format file contains list of all deviations from original sequence for other samples.See example file for details |
| annotation | optional | This text format file contains annotation. Each line of the file contains description of one annotated region and starts with three fields separates by space: annotation_type start_pos_on_query end_pos_on_query. Other fields will be ignored. See example file for details |
| Protein alignment | optional | This FASTA format file contains protein alignment aligned to the main sequence. See example file for details |
The distributive package contains some example files. The start.bat will run GeneSNP-VISTA with these input files: -rs=ABO.fsa -an=annot.txt -pb=abobg.prettybase.txt -pa=boproteinalignment.mfa and user can edit the start.bat file by using the right button of the mouse and replace the name of the files by yours. See Usage section for details. If program will found that some mandatory files were omitted it will open a Wizard window so you can open necessary files at program startup.
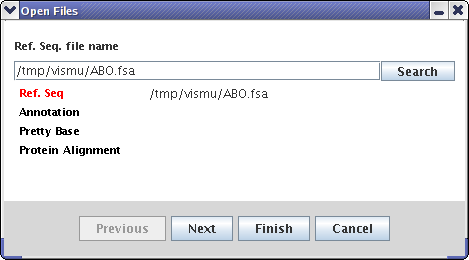
| Relation between wizard and command line parameters | |
|---|---|
| Wizard parameter | Command line parameter |
| Ref. Seq | -rs |
| Annotation | -an |
| Pretty Base | -pb |
| Protein Alignment | -pa |
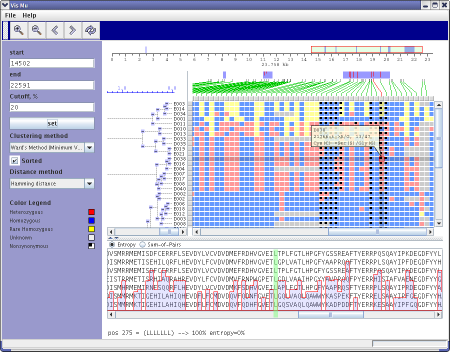
Overview of the display
Click on any part of the image to see details
Toolbar

 |
 |
Zoom in or zoom out view window |
 |
 |
Scroll left or right 1/2 window width from current position |
 |
Recalculate tree and rebuild view |
Control Panel
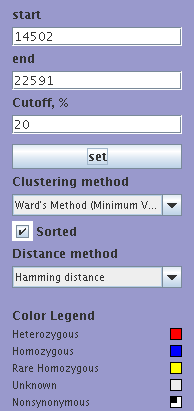
Control Panel contains the following elements:
|
Coordinate ruler

The top panel of the program shows annotation in gene coordinates. Semi-transparent red rectangle shows current position relative the whole gene length. You can drag this rectangle by mouse to change current position or drag left or right rectangle borders to change start or end position respectively.
Tree Panel
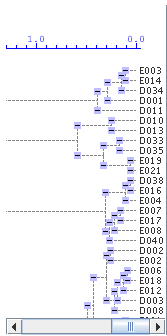
|
Tree panel reflects results of clustering procedure. Tree panel is mouse clickable. Each click on small blue rectangles will hide corresponding branch of the tree. Repetitive click in the same rectangle will show hidden branch. After each tree recalculation tree panel will show the whole tree with all branches visible. |
Zoom Panel
Zoom panel shows positions of mutation points on the zoomed area of the first sequence and points to their positions on the mutations panel.

Mutation Panel
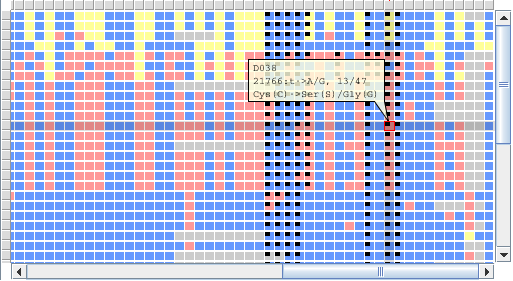
Protein alignment panel

Status Bar
Status Bar is used to show current status messages and contains progress bar

Usage
java [-Xmx###M] -classpath "... ..." DTree parameters
For classpath details see corresponding starting script.
| Parameter | Default | Comment |
|---|---|---|
| -cl | ./cluster | Path to cluster program |
| -rs | Fasta File | |
| -an | Annotation File | |
| -pb | Pretty Base File | |
| -ps | Protein Alignment File | |
| -d | Debug output |
Troubleshooting
- starting scenario assumes that java executable file is available from the standard path
If it's not so you can either add your java directory to your path or you can edit scenario file (start.bat or start) and replace the "java" by its absolute path - Not enough memory error:
You can increase amount of memory available to Java machine by changing the -Xmx###M parameter.
### must be replaced by amount of memory in megabytes. Edit start or start.bat
file to increase this parameters if default value -Xmx350M is not enough for your data set.
Questions/Comments please email to vista@lbl.gov